The first one I have mentioned before. It's Eureqa from Cornell, which uses symbolic regression. There is an example on the Eureqa site that poses this sample problem:
This page describes an illustrative run of genetic programming in which the goal is to automatically create a computer program whose output is equal to the values of the quadratic polynomial x2+x+1 in the range from –1 to +1. That is, the goal is to automatically create a computer program that matches certain numerical data. This process is sometimes called system identification or symbolic regression.The program proceeds as an evolutionary search. The graph pictured below is a schematic of the way the topology of the evolved "critters" is formed.
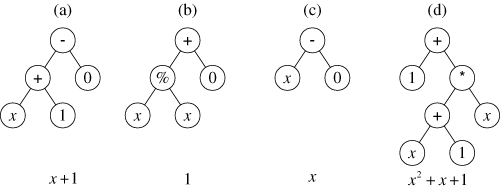 |
| A family tree of mathematical functions. (Image Source: geneticprogramming.com) |
The second data miner is aptly called MINE, and comes from the Broad Institute of Harvard and MIT. You can read about it on their site broadinstitute.org. The actual program is hosted at exploredata.net, where you can download a java implementation with an R interface. Here's a description from the site:
One way of beginning to explore a many-dimensional dataset is to calculate some measure of dependence for each pair of variables, rank the pairs by their scores, and examine the top-scoring pairs. For this strategy to work, the statistic used to measure dependence should have the following two heuristic properties.
Generality: with sufficient sample size the statistic should capture a wide range of interesting associations, not limited to specific function types (such as linear, exponential, or periodic), or even to all functional relationships.
Equitability: the statistic should give similar scores to equally noisy relationships of different types. For instance, a linear relationship with an R2 of 0.80 should receive approximately the same score as a sinusoidal relationship with an R2 of 0.80.
It's interesting that this is a generalized approach to my correlation mapper software, the difference being that I have only considered linear relationships. For survey data, it's probably not useful to look beyond linear relationships, but I look forward to trying the package out to see what pops up. It looks easy to install and run, and I can plug it into my Perl script to automatically produce output that complements my existing methods. A project for Christmas break, which is coming up fast.
Update: I came across an article at RealClimate.org that illustrates the danger of models without explanations. Providing a correlation between items, or a more sophisticated pattern based on Fourier analysis or the like, isn't a substitute for a credible explanatory mechanism. Take a look at the article and comments for more.
By coincidence, I am reading Emanaul Derman's book Models.Behaving.Badly: Why Confusing Illusion with Reality Can Lead to Disaster, on Wall Street and in Life. It has technical parts, which I find quite interesting, and more philosophical parts that leave me scratching my head. The last chapter, which I haven't read yet, advertises "How to cope with the inadequacies of models, via ethics and pragmatism." Stay tuned...
Update 2: You can read technical information about MINE in this article and supplementary material.
Update: I came across an article at RealClimate.org that illustrates the danger of models without explanations. Providing a correlation between items, or a more sophisticated pattern based on Fourier analysis or the like, isn't a substitute for a credible explanatory mechanism. Take a look at the article and comments for more.
By coincidence, I am reading Emanaul Derman's book Models.Behaving.Badly: Why Confusing Illusion with Reality Can Lead to Disaster, on Wall Street and in Life. It has technical parts, which I find quite interesting, and more philosophical parts that leave me scratching my head. The last chapter, which I haven't read yet, advertises "How to cope with the inadequacies of models, via ethics and pragmatism." Stay tuned...
Update 2: You can read technical information about MINE in this article and supplementary material.
















{kind=link}
{kind=link}